Persistence and Recoverability on the Microsoft Platform
- 04 Mar 2019
- 9 Minutes to read
- Contributors

- Print
- DarkLight
- Download PDF
Persistence and Recoverability on the Microsoft Platform
- Updated on 04 Mar 2019
- 9 Minutes to read
- Contributors
- Print
- DarkLight
- Download PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
When developing integration solutions one of the most common capabilities you need is persistence. This is the ability for a message or process instance to be saved and then to be retried or recovered in an error scenario.
For years people in the BizTalk world have had a good understanding of the importance of this capability and how it works in that technology. If you are using the cloud parts of the Microsoft Integration Platform then you have similar capabilities in a number of the technologies and I thought it would be interesting to discuss how persistence and recoverability is implemented across the technologies.
BizTalk
In BizTalk there are persistence points at various parts of the processing of your service and message instances. These include:
Developer controlled persistence points:
- When a send shape is used in an orchestration (except in an atomic transaction)
- When the start orchestration shape is used
- At the end of an orchestration
- At the end of a transactional scope (atomic or long running)
There are also a number of occasions where the BizTalk engine may also create a persistence point. These include:
- When the system shuts down unexpectedly
- When an orchestration instance is suspended
- When the orchestration instance is dehydrated
In terms of behaviours, the above points result in BizTalk behaving in the following ways:
- When a send port is initiated then it will attempt to send the message. If an error occurs then a number of retries will be made. If all of the retries are used then the instance is suspended and is persisted in the BizTalk message box so that it can be made active again later by resuming the instance where it will begin the cycle of attempting to send again.
- In an orchestration there are the various points where state is saved. These persistence points (listed above) are points where BizTalk can recover from if the system goes off line or if there is an error requiring an administrator to resume an instance.
The implementation of persistence and recovery in BizTalk is pretty powerful. Although the implementation hasnt really changed for years it gives you the ability to have the system recover scenarios for you automatically and also for scenarios where the administrator can recover from errors by resuming an instance.
Logic App
The interesting thing about Logic Apps is that the conversation about persistence points doesnt really happen yet a Logic App clearly persists its state on Azure on each action (or at least each send/API Connector action). You can see this when you get an error and you can retry the instance of the Logic App that got the error. It will resume from the shape where the error occurred.
Note this is a difference in behaviour to BizTalk where the resumption is at the last persistence point before the error occurred.
It is really interesting that in BizTalk people always used to be very cautious about the number of persistence points in a process due to the performance overhead but with Logic Apps it doesnt really come up in the discussion. I guess this is a combination of Microsoft managing the infrastructure so you dont care about the overhead and possibly the way it is implemented so you dont necessarily notice the persistence.
Logic Apps have the capability to define retry policies which allow you to have quite a good level of capability to control how retries are managed before the default Error and Retry from the administrator functionality kicks in.
Service Bus Messaging
Azure Service Bus messaging has queues which have messages on them, by default a queue in Service Bus has the message persisted so that if there is a problem it can be recovered later. There are scenarios such as experss queues where you can change this behavious but by default you get persisted messages.
When a receiver is trying to get a message, if there is a problem then the message is released back to the queue and a retry process kicks in. If the message can not be received after retries are exhausted then the message is placed on the dead letter queue from where an administrator can recover the message and resume the delivery cycle.
In Azure Service Bus its important to note that the delivery approach behaviour is affected significantly depending on if the receiver used a Peek/Lock/Delete approach vs a Receive and Complete approach.
Peek/Lock/Delete means you will use Service Bus's persistence and retry capabilities.
Receive and Complete means the message will be removed from Service Bus and its the responsibility of the Receiver to handle and problems processing it. There will be no retries or dead lettering from Service Bus.
Azure Functions
Azure Functions dont really offer any persistence and recoverability by default. If your function fails then you need to execute it again.
One point to note however is that the bindings you use in a function may mean that you are combining a function with another technology that does offer persistence and recoverability. An example of this would be if your function was receiving from Service Bus then you could configure the scenario so the retry and deadletter features of Service Bus were used allowing the function to retry automatically if there was an error.
Event Hub
Event Hub also offers persistence and retry for events sent to a hub, but it works quite differently to Service Bus messaging. The Event Hub is basically a stream of persisted messages. Every message sent to the hub is persisted to the stream for a period of time which is definted when setting up the hub. Where as Service Bus messaging requires a receiver to remove a message from a queue, the difference with Event Hub is the receiver doesnt remove messages and instead the receiver simply has a read-only cursor which allows the receiver to read the stream.
Its possible for many receivers to all have their own cursor on the stream and to read from different positions. The below diagram shows this.
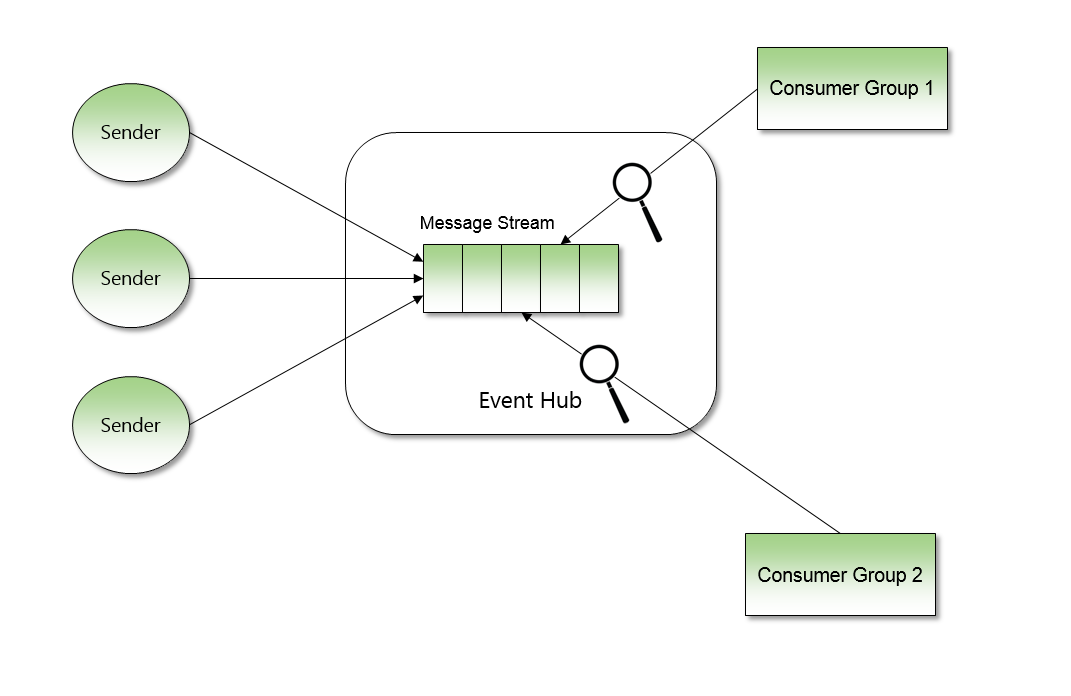
In terms of persistence and recoverability this means all event messages are on the stream for as long as is configured (eg 30 days). It is also possible for a receiver to rewind their cursor so they can re-read the stream. EG from being at current position 1000 they could rewind to position 500 and re-read those events.
This means that for Event Hub scenarios there isnt that much of a requirement for the receiver to implement persistence or retry, as long as the events are idempotent then they can just be reread.
Event Grid
Event Grid also offers durability and recoverability of events, but again the implementation is subtly different. The main reason for this is that Event Grid doesnt rely on the receiver of the event to pull messages to it, instead it will push messages to an endpoint.
The default behaviour for Event Grid is that it will attempt to deliver the event. If the sending of the event isnt acknowledged then it will attempt again to deliver. Event Grid will implement a back off policy but continue to attempt to deliver but at less frequent times for up to 24 hours. At this point it will then deadletter events to a storage account.
Scenarios to think about
As you could see above there are now a number of different ways the persistence/durability and recovery of messages and processes is implemented across the technologies available to us. I think what is interesting from an architects perspective is when I am combining services together where both offer some kind of capability then which do I use.
Logic App + Service Bus
Imagine a scenario where I have a queue which receives messages. I then have a Logic App which processes these messages from the queue and saves them to a database.
I have two options available to me.
Option 1
This would involve using the Service Bus Receive message trigger with the Auto-Complete option. This means that when the message is received it is also deleted from the queue. If the database is unavailable and I get an error then the Logic App will implement its retry policy and eventually fail and I will be able to resubmit for retry when everything is OK.
Option 2
In option 2 I would receive the message in the Logic App with the peek lock trigger. I would then call the database and use the Service Bus complete message action to remove the message from the queue at the end.
In this scenario if there was an error calling the database then two things would happen. Firstly the Logic App instance would retry then fail and leave me with an instance of the Logic App I could retry. The lock on the Service Bus message would also expire and the message would drop back to the queue and be picked up by another Logic App and be retried and possibly fail again. Eventually if the error continues then the message would dead letter on Service Bus.
With option 2 I also have considerations about how I use the retry policy and also when I complete the Service Bus message. If for example I complete the message before calling the database but then get an error calling the database then I am in the same position as option 1. If I have a retry policy that takes too long to run then my lock on the Service Bus message could expire causing the message to be released on the queue and picked up by another Logic App. The same message is now being processed by 2 Logic App instances and if the error policy worked its possible we could end up with duplicates.
BizTalk sending a message to a Logic App
If you are combining BizTalk and Logic Apps then you have a very similar scenario to Logic Apps and Service Bus.
The behaviour you will get really depends at the point the Logic App sends a response back to BizTalk. If the response is before downstream processing then there is a clean handover in responsibility for recovering from an error. If the response is after Logic App downstream processing then its possible you could end up with errors in both BizTalk and Logic Apps for the same error.
Summary
When I think back through this article, its clear that we have plenty of capability in this area to do many of the things we would want our solution to do. The key thing however is when combining technologies (which is very common) then you need to be clear what your strategy is for recovery from errors and problems. Hopefully the examples above have clarified what can happen if you set your scenario up in a way that conflicts. Im sure there are a bunch of other possible scenarios which can work and conflict and I will add these in due course but in the meantime I thought this area was an interesting topic.
Was this article helpful?